什么是 RAG
RAG 的全称是 Retrieval-Augmented Generation,中文通常翻译成「检索增强生成」,指的是对大语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源外的权威知识库。 RAG 是一种在大语言模型诞生之后为了提升大语言模型回答精确度的架构。
- Retrieve,检索,用户 Query 调用搜索引擎 API, 获取搜索结果
- Augmented,增强,设置提示词,将检索结果作为上下文
- Generation 生成,大模型回答问题,标注引用来源
Generation
我们首先从 Generation (生成)开始解释,现在大语言模型(LLM)的文字生成能力都非常强大,用户可以直接通过自然语言「询问」大语言模型「问题」,这个过程通常中用户的问题通常被称为「Prompt」,而大语言模型会根据自身训练好的数据组织答案并回答用户。比如用户询问大语言模型「太阳系中哪个行星的卫星最多?」,那如果没有 RAG,大语言模型会根据自己训练所获得知识回答,比如大语言模型可能回答(可能不准确)「木星,拥有 92 颗卫星」。
那我们分析一下这个答案,它存在两个问题,第一个问题就是这个信息没有可靠的来源,第二个问题就是这个答案可能是过时的,它可能是正确的,也可能是错误的,在 2023 年之前可能是正确的,但是之后科学家又发现了大量土星的卫星,那如果大语言模型是在 2023 年之前训练的,可能就没有这部分信息。
所以这就回答了,我们为什么要 RAG?
RAG 主要是为了解决如下两个问题。
- 没有可信的来源
- 过时的答案
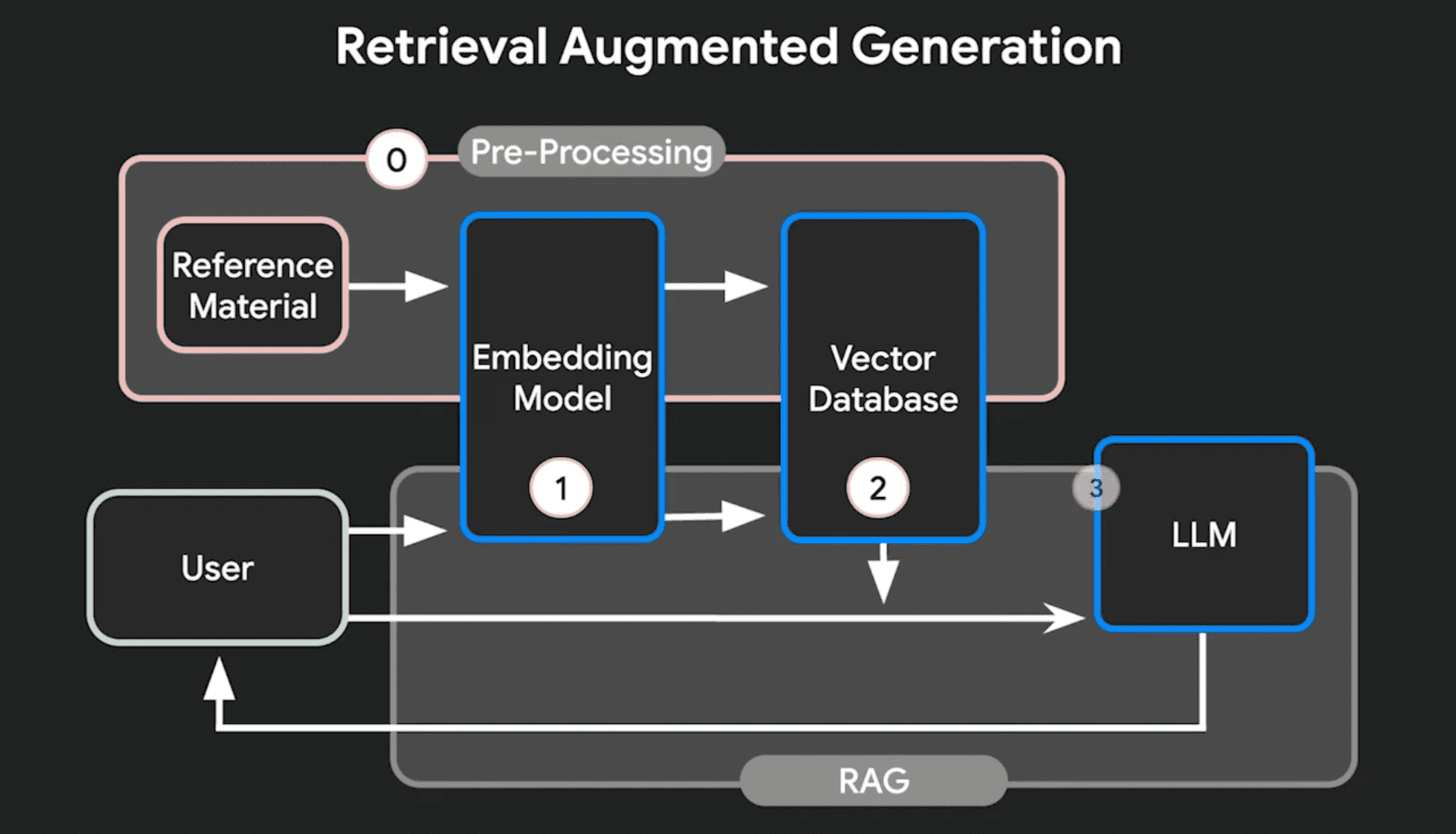
Retrieval Augmented
Retrieval Augmented 检索是 RAG 另外的核心,在检索的时候,会首先接收用户的查询,通过检索模块从预定义的知识库中查询相关的文档,这一步通常涉及到高效的向量搜索技术,将文档和查询映射到相同的向量空间,快速计算出查询相似度,然后检索模块会返回若干和查询相关的文档,将这些文档作为生成阶段的重要输入。
然后在进入生成(Generation)阶段,系统将检索到的文档和原始查询一起提供给大语言模型,比如 GPT,Claude 等,利用检索阶段获得最新的信息来生成回答。从而使得 LLM 的回答更加精确并且提供可信的来源。
RAG 技术的难点
首先构建一个高质量的信息来源非常重要,而在接收到用户查询到快速检索出相关的信息也是 RAG 检索模块最重要的一个能力。检索模块的效率和准确性直接影响了 RAG 系统的性能。
为了构建一个高效的检索系统,通常 RAG 需要的技术包括[[向量数据库]](Vector Database),文本分割器,嵌入模型(Embedding Model)。向量数据库存储了文档的向量表示,支持快速的相似度搜索;文本分割器负责将原始文档切分成适当大小的块;嵌入模型则将文本块转换为向量形式。
使用相同的 Embedding Model 才能保证用户的查询和既存信息的相似度。
RAG 的优点
- RAG 有效地减少了 LLM 的幻觉问题,让模型在缺乏知识的情况下也不会随意生成虚假信息
- RAG 提供了更高的透明度和可解释性
- RAG 让大语言模型无需重新训练就可以获得新知识的能力,大大降低了训练成本
related
- [[Fine tuning]]