之前的文章和视频里面介绍了很多国外公司发布的 AI 模型,从 OpenAI 发布的 GPT-3, GPT-3.5 Turbo,GPT-4 Turbo,GPT-o1,o1-mini,4o 等,到 Anthropic 发布的 Claude 3 Opus, Claude 3.5 Sonnet ,Claude 3.5 Haiku,再到 Google 发布的 Gemini 1.5 Pro,Gemini 2.0 Flash 等,以及在这些模型基础上开发出来的很多产品应用,ChatGPT,Claude,Gemini 等。但是最近有有一家国内创业公司接连发布了 DeepSeek V3 模型,DeepSeek R1 模型,这是一个可以媲美 OpenAI 和 Google 等公司最新 AI 模型的开源模型。
DeepSeek 是什么
DeepSeek 直接在 GitHub 公开了其开源模型 DeepSeek V3 以及 DeepSeek R1
DeepSeek 在论文中介绍了他们在训练系统时只使用了少量的芯片。美国对芯片的出口管制迫使中国的研究人员利用更少的资源,免费的工具来充分发挥创造力。DeepSeek 只花了约 600 万美元的资金就训练了新的模型,这个资金不到 Meta 训练新模型所耗资金的十分之一。世界领先的 AI 公司都投入大量的 GPU 芯片来训练他们的模型,可能多大 1.6 万个芯片,但是 DeepSeek 的工程师,只使用了 2000 个英伟达的芯片。
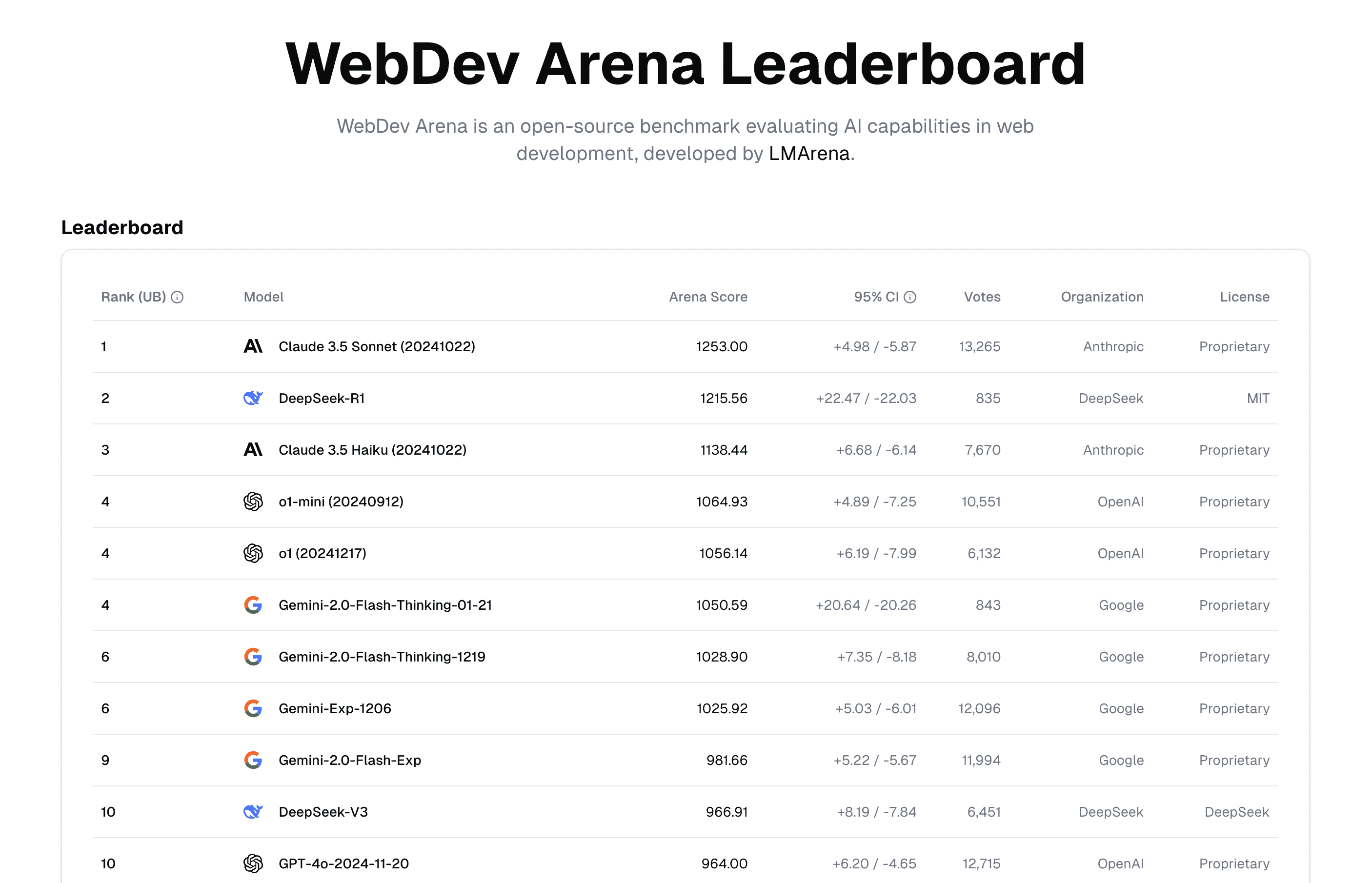
DeepSeek R1 跻身大模型排行榜前三,超越了 o1,o1-mini,Gemini 2.0 Flash Exp,略落后于 ChatGPT 4o 以及 Gemini 2.0 Flash Thinking 模型。
DeepSeek 的背后
DeepSeek 由一家叫做 High Flyer (幻方量化)的量化股票交易公司运营。
梁文锋是 DeepSeek 的灵魂人物,其背景和经历也颇为传奇,浙江大学信息与电子工程学专业本硕毕业,2008 年毕业之后,开始探索全自动量化交易,2015 年联合成立幻方量化,成为国内量化私募的四大天王,2023 年创立 DeepSeek ,进军通用人工智能领域。
DeepSeek 的技术团队主要由清华、北大等顶尖高校的应届生组成,DeepSeek 团队在短时间内取得了多项技术突破,MLA(Multi-head Latent Attention)新的注意力机制,大幅减少计算量和推理显存。GRPO(Group Relative Policy Optimization)强化学习对齐的创新算法。
DeepSeek V3 模型以十分之一的算力超越了 Llama 3,展现了极高的性价比。
创始人在 2023 年 5 月和 2024 年 7 月分别接受了暗涌的采访
- 疯狂的幻方 一家隐形 AI 巨头的大模型之路
- 一家特立独行的量化基金公司下场
- 从远处说,我们想去验证一些猜想。比如我们理解人类智能本质可能就是语言,人的思维可能就是一个语言的过程。你以为你在思考,其实可能是你在脑子里编织语言。这意味着,在语言大模型上可能诞生出类人的人工智能(AGI)。
- 我们现在想的是,后边可以把我们的训练结果大部分公开共享,这样可以跟商业化有所结合。我们希望更多人,哪怕一个小 app 都可以低成本去用上大模型,而不是技术只掌握在一部分人和公司手中,形成垄断。
- 创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。创新往往都是自己产生的,不是刻意安排的,更不是教出来的。
- 创新就是昂贵且低效的,有时候伴随着浪费。
- 务必要疯狂地怀抱雄心,且还要疯狂地真诚
- 揭秘 DeepSeek:一个更极致的中国技术理想主义故事
- 我们不会闭源。我们认为先有一个强大的技术生态更重要。
- 更多的投入并不一定产生更多的创新。
- 我们每个人对于卡和人的调动是不设上限的。如果有想法,每个人随时可以调用训练集群的卡无需审批。
- 我觉得创新首先是一个信念问题。为什么硅谷那么有创新精神?首先是敢。Chatgpt 出来时,整个国内对做前沿创新都缺乏信心,从投资人到大厂,都觉得差距太大了,还是做应用吧。但创新首先需要自信。这种信心通常在年轻人身上更明显。
- 以后硬核创新会越来越多。现在可能还不容易被理解,是因为整个社会群体需要被事实教育。当这个社会让硬核创新的人功成名就,群体性想法就会改变。我们只是还需要一堆事实和一个过程。
DeepSeek 为什么这么强
强化学习
DeepSeek R1 在后训练大量使用了强化学习,在极少标注数据的情况下,极大地提升了模型的推理能力。
DeepSeek 模型团队在训练 R1 的过程中,直接实验了三种截然不同的技术路径,直接强化学习(R1-Zero),多阶段渐进训练(R1)和模型蒸馏。直接强化学习这一个路径,DeepSeek-R1 是第一个证明了这一方法有效的模型。训练 AI 的推理能力传统的做法是通过在 SFT(监督微调),加入大量的思维链(COT) 范例,用例证和复杂的过程奖励模型(PRM)之类复杂神经网络奖励模型,来让模型学会使用思维链思考,还会加入蒙特卡洛搜索树(MCTS),让模型在多种可能中搜索最好的可能。但是 DeepSeek 选择了一条前所未有的道路,纯强化学习,抛开了预设的思维链模板(Chain of Thought)和监督式微调(SFT),只依赖奖惩信号来优化模型行为。就像让一个天才儿童在没有任何范例和指导下,自己不断尝试获得反馈来学习。
一个简单的流程就是,输入问题,生成多个答案,规则系统评分,GRPO 计算相对优势,更新模型。这种方法下,训练效率得到了提升,在短时间内就可以完成。1
优势
- 使用成本低,DeepSeek R1 的训练和使用成本远低于同级别的商业模型,API 定价仅仅是 OpenAI o1 的 3~4%。
Chat
DeepSeek 也提供了一个类似 ChatGPT 的网站 https://chat.deepseek.com/
扬·安德烈·勒坎(杨立昆),2018 年的图灵奖得主是这样评价 DeepSeek 取得的成就。他说这是开源的胜利。

API
DeepSeek 同样有自己的开放平台,用户可以在这里申请 API Key
问题测试
语文题

答案:海日生残夜,江春入旧年
数学题
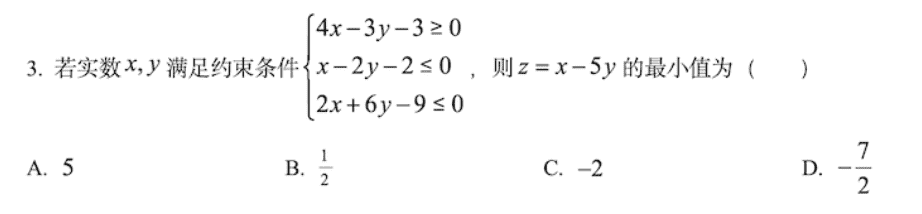
答案是 D
物理题

答案是 C
化学题
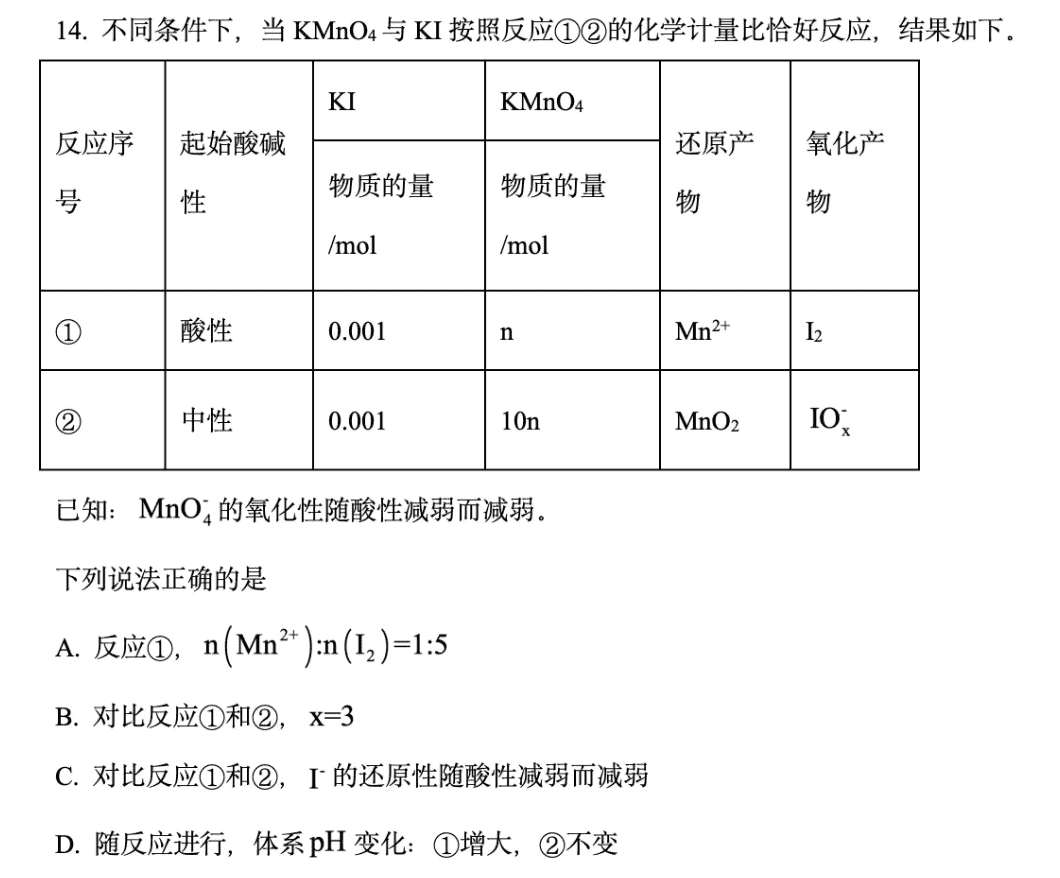
答案:B